Supervised Learning in Machine Learning

Cloud and DevOps Engineer with hands-on expertise in AWS, CI/CD pipelines, Docker, Kubernetes, and Monitoring tools. Adept at building and automating scalable, fault-tolerant cloud infrastructures, and consistently improving system performance, security, and reliability in dynamic environments.
Introduction
Supervised learning is one of the most popular techniques in Machine Learning, where the model is trained on labeled data. It learns to map input data (features) to output labels, enabling it to make accurate predictions on new data. Supervised learning algorithms are categorized into two main types:
Regression Algorithms – Predict continuous values.
Classification Algorithms – Predict discrete classes or categories.

1. Regression Algorithms
Regression algorithms are used when the output variable is continuous, such as predicting house prices, stock values, or temperatures.
1.1 Linear Regression
Linear Regression establishes a linear relationship between the input (X) and output (Y) variables. It assumes that the change in the output variable is proportional to the change in the input variable.
Equation of Linear Regression:

Where:
Y = Predicted output
X = Input feature
b0 = Intercept
b1 = Slope (coefficient)
ε = Error
Example Code:
from sklearn.linear_model import LinearRegression
X = data[['Feature']]
y = data['Target']
model = LinearRegression()
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Simple to implement and interpret.
Efficient for small to medium-sized datasets.
Limitations:
Assumes a linear relationship between input and output.
Sensitive to outliers.
1.2 Polynomial Regression
Polynomial Regression is an extension of Linear Regression that models the relationship between input and output as an nth-degree polynomial.
Equation of Polynomial Regression:

Example Code:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X)
model = LinearRegression()
model.fit(X_poly, y)
predictions = model.predict(X_poly)
Advantages:
Captures non-linear relationships.
Flexible with degree adjustment.
Limitations:
High-degree polynomials can overfit the data.
Computationally expensive for high dimensions.
1.3 Quantile Regression
Quantile Regression estimates the conditional quantiles of the output variable, such as the median (50th percentile), 25th, or 75th percentiles. This makes it robust to outliers and useful for predicting ranges instead of point estimates.
Equation of Quantile Regression:
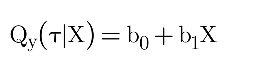
Where τ is the quantile being estimated (e.g., 0.5 for median).
Example Code:
from sklearn.linear_model import QuantileRegressor
model = QuantileRegressor(quantile=0.5)
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Robust to outliers.
Predicts ranges and percentiles.
Limitations:
Requires more computational resources than linear regression.
Interpretation is more complex.
2. Classification Algorithms
Classification algorithms are used when the output variable is categorical, such as predicting email spam (Yes/No), disease diagnosis (Positive/Negative), or image recognition (Cat/Dog).
2.1 Logistic Regression
Logistic Regression is used for binary classification problems. It calculates the probability of an event occurring using the sigmoid function.
Equation of Logistic Regression:

Example Code:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Simple to implement and interpret.
Outputs probability scores.
Limitations:
Assumes a linear relationship between input features and the log odds.
Not suitable for non-linear decision boundaries.
2.2 Decision Trees
Decision Trees use a tree-like structure to make decisions. They split the data into branches based on feature values, leading to a final decision.
Example Code:
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Easy to interpret and visualize.
Handles non-linear relationships.
Limitations:
Prone to overfitting.
Unstable to small changes in data.
2.3 Random Forest
Random Forest is an ensemble learning method that builds multiple decision trees and combines their predictions.
Example Code:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Reduces overfitting.
High accuracy and robustness.
Limitations:
Complex to interpret.
Computationally expensive.
2.4 Support Vector Machines (SVM)
SVM finds the optimal hyperplane that separates data into classes with the maximum margin.
Example Code:
from sklearn.svm import SVC
model = SVC(kernel='linear')
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Effective in high-dimensional spaces.
Works well with non-linear boundaries using kernel trick.
Limitations:
Sensitive to outliers.
Computationally expensive for large datasets.
2.5 k-Nearest Neighbors (k-NN)
k-NN is a non-parametric algorithm that classifies a data point based on the majority label of its k-nearest neighbors.
Example Code:
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Simple and easy to implement.
No training phase; fast for small datasets.
Limitations:
Computationally expensive for large datasets.
Performance depends on the choice of k.
2.6 Naive Bayes
Naive Bayes is based on Bayes’ theorem and assumes independence among predictors.
Example Code:
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X, y)
predictions = model.predict(X)
Advantages:
Fast and efficient.
Performs well with high-dimensional data.
Limitations:
Assumes independence among features.
Not suitable for correlated features.
Conclusion
Supervised learning is the backbone of most ML applications. Choosing the right algorithm depends on the problem type, dataset characteristics, and desired outcomes. In this blog, we explored the key algorithms in Regression and Classification, laying a strong foundation for future ML projects.




